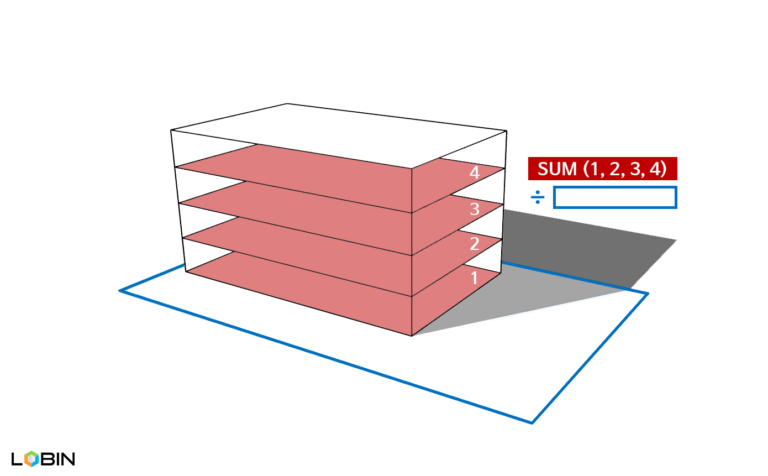
용적률은 건축물의 밀도에 대한 대표적인 규제 지표입니다. 특정 대지에 건축물을 어느 정도의 밀도로 건축할 수 있는지를 직접적으로 나타내기 때문입니다. 이러한 이유로, 용적률은 대지의 가치에 직접적인 영향을 주는 지표의 하나이기도 합니다. 같은 면적의 두 대지 중, 훨씬 더 많은 세대의 아파트를 지을 수 있는 대지가 훨씬 더 많은 수익을 창출할 것이기 때문입니다.
밀도의 중요성이 증가하게 된 데에는 크게 두 가지 요인이 있습니다. 첫번째는 산업구조가 농업 중심에서 공업 중심으로 바뀌면서 진행된 급격한 도시화입니다. 이 시기에 물류의 편의성으로 모든 자원이 집결 및 분배되던 지역들로 농촌의 인구가 이주해 정착했습니다. 두번째는 고층 건축 기술의 발전으로 이처럼 늘어난 인구를 수용할 수 있는 용량이 확보된 것입니다. 이로 인해 초창기 열악했던 도시의 생활 환경은 빠르게 개선되었습니다. 그리고, 교육, 의료, 행정 등의 서비스를 가까운 곳에서 제공받을 수 있는 도시의 생활 환경은 도시화를 더욱 가속하게 됩니다.
용적률의 개념은 이러한 도시화와 고층 건축 기술의 선도 주자였던 미국에서 1961년 처음 도입되었고, 우리나라 건축법에 용적률의 개념이 처음 등장한 것은 그로부터 12년이 지난 1973년입니다. 이후 용적률은 ‘자산’의 개념으로 발전해, 미국의 경우 사용하지 않은 용적률을 인접한 대지에 양도할 수 있도록 허용하고 있습니다. 우리나라에서도 이에 대한 도입이 오랜 기간 검토되고 있으나, 시효가 지난 특별법이나 온전히 실현되지 못한 도시계획 등에 따른 용적률 특례와 관련된 논란의 여지가 먼저 해소될 필요가 있을 것으로 판단됩니다.
